
前言
网易云音乐 PC/MAC/Linux 这三大桌面端,均采用了在原生应用中嵌入前端页面的方式。
通俗地说,就是将一个本地的 HTML 页面在浏览器中打开,但这个浏览器内嵌在云音乐桌面应用内。我们云音乐前端技术团队负责开发这个 HTML 页面,需要在这个页面中使用 JavaScript 相关技术绘制界面,并控制这个页面的交互。播放器、桌面歌词等内容则采用原生技术开发,并在 JS 中注入接口,以供前端调用。
我们需要在这个单一的页面中�,为用户提供桌面应用级的体验。在现有的方案中,我们也遇到一些应用体验不佳、开发效率低的问题。在最近一年里,我们也在寻找一些更好的解决方案,期望做得比以前更好。我们调研了一些解决方案,最终决定引入 RxJs,设计一套全新的数据层。
本文会以云音乐桌面端的场景为例,先介绍为了实现桌面应用级的体验,我们的目标是什么,再看看过去我们为了这些目标面临了哪些挑战,最后谈到我们目前在做的,使用 RxJs 应对这些挑战的一些探索。
我们的目标
单页
首先,作为一个桌面端应用主界面的构成,任何交互操作中不能出现空白的画面;数据层的数据也需要持续保留,因此这必须是一个单页页面。
本地缓存
例如在歌单场景中,需要一套缓存机制,保存歌单中歌曲的基本信息,以便在播放歌曲、下载歌曲时,避免重复向服务端请求歌曲的详情数据。特别是一些歌单,歌曲数量可以多达一万首,这套机制尤为重要。
持久化
最基本的,例如需要对播放列表进行存储,以便用户在下次打开云音乐时还能继续使用上次关闭前的播放列��表。
若想继续提升用户体验,对于用户创建的歌单,作为用户高频访问的内容,也需要进行持久化的存储,从而提升歌单的访问速度,以减少用户的等待时间。
内存管理
常规的 web 应用或许不需要考虑这方面的问题。但是,作为桌面端应用,当用户一直未关闭应用,并访问了几百上千个页面,如果不进行内存管理,这些页面缓存的数据,一直存放着,那么此处应用程序也许会发生崩溃。我们需要尽量完美的内存控制,以保持我们作为桌面应用的稳定性,当然这很难。
代码层面上的挑战
关联数据的处理
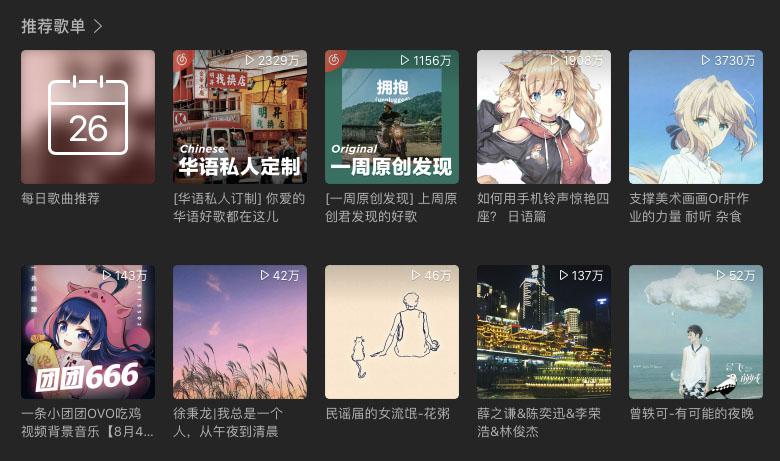
以首页的推荐歌单为例,这是一个有序列表,列表中存放的是各个歌单数据。
直接使用下方这样的树状结构进行存放,展示起来很方便。
list = [{
'id': 54321,
'name': '[华语私人订制] 你爱的华语好歌都在这儿',
'copywriter': '编辑推荐:无论新歌老歌,都是耐听的华语好歌',
'playCount': 23298238,
'trackCount': 35,
'coverImgUrl': 'https://p3.music.126.net/KEBE7CU-y2lInkHBcgzpUA==/109951164173101961.jpg'
}, {
'id': 1234,
'name': '[一周原创发现] 上周原创君发现的好歌',
'copywriter': '编辑推荐: 遇见全新面孔,邂逅熟悉声线',
'playCount': 11565127,
'trackCount': 30,
'coverImgUrl': 'https://p3.music.126.net/09o_XZbuG0TFWnNGAKuV5w==/109951164321476771.jpg'
},
...
];
但是如果其中有一些歌单,同时是当前用户创建的歌单,按上面这个方法又存放了一份歌单数据。当用户修改这个歌单时,如何确保两份歌单数据都能得到更新?
有一种方法是,使用 map 的结构,id 为 key,数据为 value。不同列表中对这个歌单的数据,都是对 map 中这个歌单的引用。也就是对同一个数据项,做了多重索引。
playlistMap = {};
playlistMap[54321] = {
'id': 54321,
'name': '[华语私人订制] 你爱的华语好歌都在这儿',
'copywriter': '编辑推荐:无论新歌老歌,都是耐听的华语好歌',
'playCount': 23298238,
'trackCount': 35,
'coverImgUrl': 'https://p3.music.126.net/KEBE7CU-y2lInkHBcgzpUA==/109951164173101961.jpg'
};
playlistMap[1234] = {
'id': 1234,
'name': '[一周原创发现] 上周原创君发现的好歌',
'copywriter': '编辑推荐: 遇见全新面孔,邂逅熟悉声线',
'playCount': 11565127,
'trackCount': 30,
'coverImgUrl': 'https://p3.music.126.net/09o_XZbuG0TFWnNGAKuV5w==/109951164321476771.jpg'
};
list = [playlistMap[54321], playlistMap[1234]];
这样对视图来说,依然是树状结构,当若修改了 map 或者 list 里面的某个数据,另外几处也会得到修改,因为完全是相同的引用。
但要想让视图层关联的内容刷新,你需要再加一套事件机制,提示视图去刷新。发布事件,视图层订阅事件,两者缺一不可。
在实际的场景中,情况会更复杂。例如歌单里面嵌套了创作者、歌曲列表这样的数据,歌曲列表有序存放着歌曲,单个歌曲则可以嵌套多个歌手,嵌套专辑数据。在歌单详情页中,这些数据均需要展示。
如果使用 React + Redux 这样的方案,基于不可变数据的原则,这种方式就不适用了。我们修改了一个数据项,需要复制一个新的对象,所有引用到这个数据项的地方都要用新的对象去替换,这是非常繁琐的。
因此有一些方案中,提出对数据保持扁平,遇到这种层层嵌套的数据,进行范式化处理。前面提到的这种引用,我们改为存储 id 来描述引用关系。这样数据项只在一个地方定义,当其需要更新的话无需在多处改变。这是个不错的想法,但这不能解决数据更新后视图同步刷新的问题。你需要在多个 reducer 中处理这些数据,有些繁琐,代码也不是特别清晰。
关联的计算
如果我们说,关联的数据指的是数据间能够用引用关系去描述关联。那么实际上还有一种关联。例如,用户的会员状态,与一首歌曲,表面上并没有引用关系,但隐藏的情况是:歌曲中会有一些内容用来描述用户对这个歌曲拥有的权限,例如能否播放这个歌曲,而有一些歌曲是仅限会员播放的。当用户的会员状态变化时,需要把歌曲权限更新到最新状态。
其实这代表了一种情况,某个事件发生了,需要推动一系列数据去变更,或者说需要对其他的一系列数据做一次新的计算。a = b + c,b 或 c 变化的时候需要重新计算 a。传统的做法,是 b 发生变化,通知 a 模块,a 需要监听到这条消息,重新去获取 b 和 c 的值,从而重新计算。c 发生变化,亦是如此。其缺点就是比较麻烦,可读性也不强。
当然有更复杂的情况,比如在 a = b + c 中,希望 b 和 c 均在经历一次变动过后,才重新计算 a。此时就需要写另外一段代码来处理这个问题了。
逻辑复杂
查询同一种数据,可能从缓存中获取,那是同步的。如果是 Fetch 请求,那是异步的,业务代码编写需要考虑两种情况。大致的代码如下:
const data = getItemInCache();
if (data) {
render();
} else {
getItem();
}
on('itemGet', () => {
render();
});
如果按照获取数据的来源分类,Fetch 请求,DB,LocalStorage,获取文件缓存,这些都是拉的操作,也就是获取数据的操作。WebSocket,用户的输入,则是推的操作,是数据的更新通知。他们的代码是这样的:
// 拉
getSomething().then(() => {
// do
});
// 推
on('somethingPush', () => {
// do
});
有时对同一种数据进行更新,但是因为推和拉不同的来源,需要两份代码,加大了代码编写的复杂度。
对于这类问题,有如下大致的解决方式:
const changeTodo = todo => {
dispatch({type: 'updateTodo', payload: todo});
}
const changefromDOMEvent = () => {
const todo = formState
changeTodo(todo);
}
const changefromWebSocket = () => {
const todo = fromWS
changeTodo(todo);
}
但是这种方式还有个问题,我们没法清楚地看到一条数据的来龙去脉。此外,事件的发布与订阅者,经常位于不同的模块中,需要封装良好的自定义事件,以便事件的订阅者分辨事情的来源,以及它需要去做什么。
内存管理
这个事情很棘手。在目前版本的云音乐桌面端中,我们没有找到有效的办法去管理,只能设置定时器,手动去寻找一些可能无用的缓存数据,然后去清理他们。
我们的应对
首先需要说明的是,以下内容是我们目前在做的,利用 RxJs 解决这些问题的一些探索。离这些内容正式上线还有一段路要走。如果读者对这些方案存在疑问,欢迎与我们交流。
假设读者已经对 RxJs 有一些简单的了解(学习 RxJs 相关内容可以移步到官网)。比如说,对于上面 a = b + c 这个问题,你需要知道 RxJs 里可以这样做:
const b$ = new Rx.Subject();
const c$ = new Rx.Subject();
const a$ = b$.combineLatest(c$, (b, c) => b + c);
a$.subscribe(c => console.log(`a=${a}`));
b$.next(1);
c$.next(1);
// a=2
c$.next(2);
// a=3
b$.next(10);
// a=12
我们看看 RxJs 为我们带来了什么。
RxJs 处理复杂的逻辑
对于查询一份数据遇到的同步与异步两种情况,我们可以做如下的事情:
const data$ = () => {
if (cache) {
return Rx.of(cache);
} else {
return Rx.fromPromise(fetch(url));
}
}
data$.subscribe(data => {
// do
});
可以看到,我们查询这份数据,优先读取缓存,这是同步的操作;如果缓存无效,进行了一次异步获取数据的操作。视图层只需要执行一次对数据的订阅即可。
接下来处理数据多种来源中推与拉两种不同方式的问题。
首先,RxJs 支持将所有内容封装为数据流。无论是 Fetch 请求,DB,LocalStorage,获取文件缓存的操作,还是 WebSocket,用户输入的事件,统统可以封装成数据流,然后交给视图层去订阅,而不需要在不同数据来源拿到数据后,考虑怎么交给视图层。
const dataFromWebSocket$ = Rx.fromEvent(ws, 'message');
data$.pipe(
merge(dataFromWebSocket$)
).subscribe(data => {
// do
});
把推送信息,和主动查询数据的两个流合并起来,供视图去订阅。不管是推还是拉的操作,从代码编写的角度,都是一个拉取的方式。因为我们写出了类似表达式的效果,一个数据流可以由其他数据流通过多种运算符来组合、转换得到。形似 a = b + c。但其实际表达的意思,却是
on('b changed', (newB) => {
a = newB + c;
// dispatch event
});
on('c changed', (newC) => {
a = b + newC;
// dispatch event
});
也就是其实是一个推送的过程。
视图层只需要去订阅数据流,而不需要考虑数据要怎么获取,数据到时候是怎么推送过来的,视图层只要专注于自己的逻辑就可以了。
此外,不管是多么复杂的逻辑,都能在 RxJs 中找到合适的操作运算符,由最基础的数据流组合、转换得到复杂的数据流供视图去订阅。例如之前提到的,在 a = b + c 中,希望 b 和 c 均在经历一次变动过后,才重新计算 a,我们就可以使用如下的操作符。
==TODO==
总结一下,我们以推荐歌单页面为例,看看其中视图与数据流大致的设计思路。
当用户访问了推荐歌单页面,视图中会执行对获取推荐歌单这条数据流的订阅。此时,这条数据流开始流动。因为是第一次获取推荐歌单��,我们还没有缓存这一部分的数据,我们去发送 Fetch 请求,Fetch 请求得到的数据,在经过一些格式化操作后,会存放为缓存。但是,我们最后提供给视图订阅的,并不是这条格式化后的数据,而是经过包装的一条新的数据流,这条数据流是在格式化的数据基础上,又与其他可能引起这些歌单的数据产生变化的数据流组合而来。
当推荐歌单这一部分数据中,任意歌单数据发生变化,都会引起数据流新的流动,从而去推动视图进行变更。
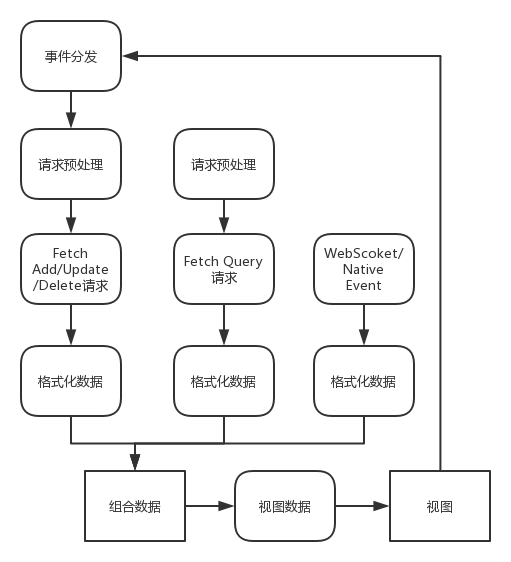
另外需要注意,视图只要做一次对数据流的订阅即可,而不需要执行类似 dispatch action 这样的操作。除非是增加、删除、修改这样的操作,也就是从视图层面进行的数据的写入,需要做一个 dispatch action 的操作。这也简化了视图层的一些逻辑,视图不需要关心,第一次数据是怎么来的,需要拉取哪部分的数据。
选择懒执行还是预热
从前面就可以看到,视图使用数据,只需要对数据流进行订阅。反过来思考,当视图没有对数据流进行过订阅时,数据流会不会流动呢?以一段代码为例:
const promise = new Promise((resolve) => {
console.log('Hello');
resolve(1);
});
代码运行后会输入 Hello 。但换成 RxJs 的 Observable:
const foo$ = Rx.create((observer) => {
console.log('Hello');
observer.next(1);
observer.next(2);
observer.next(3);
});
这段代码没有任何输出。
与 Promise 不同,当 foo$ 未被订阅,内部是未执行的状态,数据流并没有开始流动。
想想这样的好处。首先这是前面提到的,视图层只需要订阅数据流而不需要额外操作的前提。此外,在视图未订阅的情况下,推送类型的数据是不流动的,符合我们的预期,避免了无用的请求和未知的副作用。
RxJS 让我们能够精确执行向确实存在的视图的数据流推送。
当然,如果需要,我们也可以做一些预热的操作,让数据流提前流动。比如预先去 fetch 来获取到数据,等到视图订阅时,能够立刻拿到数据,提升应用程序的响应速度。使用诸如 publish 和 connect 的操作符就可以预热。这里不再详细阐述。
const source = Rx.interval(1000);
const example = source.pipe(
publish()
);
example.connect();
不需要集中的数据管理
Redux 为什么是单一 Store。其中一个原因是需要从整体的 state 结构上检出变化的部分。
但 RxJs 不需要,变更过程是精确的。数据从数据管道一直流动到视图上,而没有变化的部分就不会流动。
至于别的原因,例如方便同构应用开发,方便实现撤销/重做功能。在我们的云音乐桌面端场景上也没有这种需要。
因此,我们可以按业务划分 module 。且每个 module 中向视图暴露的其实也是一条一条数据流,你可以去订阅这些数据流。例如获取推荐歌单的数据推送,这就是歌单这个 module 中提供的一条数据流,而它由其他多个数据流组合而成。
如果是单一 Store,我们需要指定 action 去修改 state,需要区分这个 action 修改的��是 state 内的具体哪个部分。
而实际的情况是,在多个 module 中,大部分的数据是不需要跨域 module 处理的,我们关心数据在单个 module 中的流动即可;少部分情况下我们用 RxJs 的操作运算符进行组合、转换等也可以完成不同 module 间的关联数据计算。在数据流的组合操作中,天然地表明了数据流动的姿态,无需 action 来标记修改的部分。
数据管理的详细设计
前面介绍了那么多 RxJs 的好处,并说明了数据从顶部到视图层的大致流向,接下来我们需要设计,如何利用 RxJs 存放数据,并提供优质的数据流供视图订阅。
对于复杂的、嵌套的数据,我们考虑做一些范式化的操作。我们存储的是扁平的数据,通过对id的存储来描述不同类型的数据的引用关系。
例如歌单项的存放,一个歌单的数据看上去是这样的:
const playlistItem = {
name: 'xxx',
id: '123',
cloudTrackCount: 0,
commentCount: 123,
creator: {
id: '1',
name: 'aaa'
},
...
trackCount: 2,
trackIds: ['12345', '14567'],
tracks: [{
id: '12345',
name: 'abcde',
...
}, {
id: '14567',
name: 'adefg',
...
}]
};
我们需要对其进行范式化处理,例如使用 creatorId 来描述关联的是哪个用户。关联的用户数据,则作为单独的数据项存放。处理后的歌单数据是这样的:
const playlistItem = {
name: 'xxx',
id: '123',
cloudTrackCount: 0,
commentCount: 123,
creatorId: '1',
...
trackCount: 2
};
const creatorItem = {
id: '1',
name: 'aaa'
};
const trackList = {
id: 'playlist-123',
list: ['12345', '14567']
};
const trackItem1 = {
id: '12345',
name: 'abcde',
...
};
const trackItem2 = {
id: '14567',
name: 'adefg',
...
};
根据实际业务中遇到的各种场景,我们总结了常见的数据关联方式,从而提出范式化处理中的一些约定:
-
不同类型的数据声明不同的容器。同一类型的数据存放在同一种容器的实例中。这一类型的数据可以作为一个 entity 来看待;
-
将同类型的 entity 存储在 Collection 集合中,其中每个 entity 的主键
primary作为key,entity本身作为value; -
任何对单个 entity 的引用都应该根据存储的
primary来表示。需要使用时,从 Collection 中查询获取; -
针对例如歌单中的歌曲列表这样的有序列表,再定义一个List 容器,实例化的
list中应该存储 entity 的primary来引用他们。将list也存储在 Collection 集合中便于之后查找。
在声明某一类型的容器时,我们可以使用诸如 JSON Schema 的方式来描述数��据的格式,以便于进行数据校验、格式化,持久化等工作。额外添加一些属性,用数据流描述对其他类型数据的关联。
声明完这些内容后,接下来的使用就方便了。在容器的实例中,对其中任意属性进行修改,都会因为数据流的存在,流动到被其依赖的数据项中,进行同步的更新,并最终流动到视图中,视图需要什么数据项就订阅什么数据项,数据项更新的时候,或者关联的数据更新的时候,均会自动流动到视图上。
实际使用时,我们会涉及到向 Collection 查找符合条件的 entity;在 List 中 slice() 取到列表的一部分内容,以满足视图中分页的场景;针对某个 entity 订阅其中一部分属性的变化。我们使用 RxJs 的操作符实现一些自定义的方法即可。
根据以上思路,得到的设计方案大致是这样的:
以歌曲为例说明这套方案的使用方式,首先声明数据格式:
class Track extends BaseStore {
static schema = {
type: 'object',
properties: {
name: {
type: 'string',
default: ''
},
id: {
type: 'string',
primary: true
},
artistId: {
type: 'string'
}
},
required: ['id']
}
static views = {
get artist() {
return this.artistId$.pipe(
switchMap(id => (id
? ArtistStore.findOne(id).$.pipe(
map(([item]) => (item
? item.data
: null))
)
: Rx.of()))
);
}
}
}
class TrackCollection extends CollectionStore {
static entity = Track
}
const trackCollection = new TrackCollection();
注意 Track.views 的逻辑,这里的思路是,通过 views 方法表明对关联的 artist 数据的依赖。
artistId$ 表示订阅歌曲中 artist 数据的变动。这种只想订阅数据项中某个属性的变动,最简单的实现方式,就是使用 distinctUntilKeyChanged 操作符。
返回 Observable,它发出源 Observable 发出的所有与前一项不相同的项,使用通过提供的 key 访问到的属性来检查两个项是否不同。
通过这种方法,我们将不再需要类似 reselect 这样的工具。
考虑使用诸如 trackCollection.findOne(id).views('artist').$ 方法来订阅某个歌曲数据,使歌曲本身的变化,以及歌曲对应的 artist 艺人数据变化时,均能得到新的数据流动。也就是查找到的歌曲数据本身和 views 指定的 artist 查询的数据流,会合并得到新的数据流。
这里可以使用 RxJs 的 combineLatest 操作符来实现具体的逻辑。
combineLatest 结合所有输入 Observable 参数的值. 顺序订阅每个 Observable,每当任一输入 Observable 发出,收集每个输入 Observable 的最新值组成一个数组。
if (views && views.length) {
return Rx.combineLatest(
x.all$,
...views.map(v => x.views[`${v}$`]).filter(Boolean)
);
}
其中 x 是查询到的 entity,x.all$ 代表了 entity 本身的数据变动,x.views 中以 $ 为后缀的属性则代表了具体某个 view 属性,数据变动产生的数据流。
类似的方式,考虑在 List 中添加 itemViews 相关的逻辑。
class TrackList extends ListStore {
static schema = {
type: 'object',
properties: {
id: {
type: 'string',
primary: true
},
list: {
type: 'array',
items: {
type: 'string'
}
},
total: {
type: 'number'
}
}
}
static itemViews = {
items(id) {
return trackCollection
.findOne(id).views('artist')
.$.pipe(
map(([item]) => item)
);
}
}
}
class TrackListCollection extends CollectionStore {
static entity = TrackListStore
}
const trackListCollection = new TrackListCollection();
随后我们可以往 trackListCollection 插入数据,而对其数据的订阅,则可以有类似这样的操作:
trackListCollection.findOne('newsong').exec().then(([result]) => {
result.join().views('items').$.subscribe(
data => data.items.forEach(i => render({ ...i.data, ...i.views }))
)
});
通过这样的方法,可以获取到某个歌曲列表,并在任意歌曲和他们的歌手数据变动时,均有数据流动,得到最新的数据。实现思想与 findOne().$ 基本一致,此处不再阐�述。
内存管理
因为对于数据,均是通过对数据流进行订阅来获取的。当切换页面的时候,视图层会执行对某些数据流取消订阅的操作,同时也会影响关联的数据流的订阅状态。如图所示,灰色歌曲被视图取消订阅,关联的专辑或歌手数据流也能分析出是否继续被订阅:
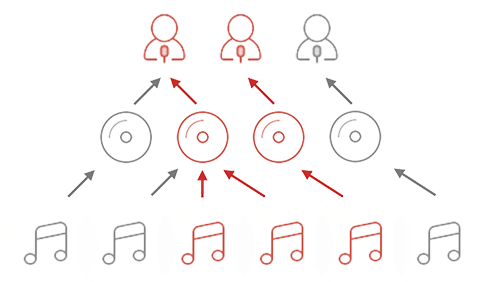
因此,对任意数据流来说,是否被订阅,可以表明视图是否在使用它。当某些数据有很长一段时间没有被订阅时,就考虑删除操作以回收内存。
我们可以开设一个定时器,去找已经取消订阅,且取消订阅时间最长的数据流,优先回收它,使缓存的数据稳定在一个能被接受的内存大小。
不过RxJs并没有直接提供获取到某个数据流的订阅数这样的方法,需要自己去实现一下。这是主要的思路:
new$ = Rx.Observable.create((subscriber) => {
const subscription = old$.subscribe(subscriber);
counter++;
return () => {
subscription.unsubscribe();
counter--;
};
});
这里对数据流再做了一次封装,counter 记录了实际订阅的个数。如果 counter 为0,你就可以考虑清除它。
还需要 Redux 吗?
有一些解决方案,例如 redux-observable,Ngrx,都将 RxJs 与 Redux 结合在一起使用,他们结合得很好。
但如果将 RxJs 仅是作为 Redux 的异步解决方案,而让视图层仍然与 Redux 接触,那其实前面说到的, RxJs 为我们带来的数据订阅,懒执行、无需单一 Store这样的特性其实就很难利用了。
何况通过 Rx 重新实现 Redux 并不难。
因此,我们完全有理由不使用 Redux。
搭配 React
如果不考虑使用 Redux,直接在 React 中订阅 RxJs 的数据流。如果你了解过 React-Hooks,可以使用 React hooks for RxJS 这套方案。
如果使用 React-Hooks 的方案,其底层实际使用的是 useState 方法,需要注意的是,这个 state 需要遵循不可变数据原则,如果对state对象进行了直接修改并返回同一对象,而不是复制数据,然后更新数据副本,useState 无效,React 会认为没有变化。因此,如果视图订阅的是单个数据项,可以将数据项另外存放在不可变的数组或者对象中,再提供给视图。
如果坚持使用高阶组件的方式,实现一个 connect() 方法连接 React 与 RxJs 也不是什么难事。
如果考虑在 React 中进行性能优化,这里提供两种选择:
-
对于单个数据流中,数据流动时,也需要遵循不可变数据原则,对于数据变换的部分,创建新的对象或者数组,以便于使用
memo()进行浅层的判等检查,从而提升性能。我们使用 RxJs 就是为了让变化的数据通过数据流流动,而不变化的数据不流动。结果到了 React 这里,我们却仍然需要关注不可变数据,是有那么一点点不太舒服。
但是好在我们做了范式化处理,数据项往往已经足够扁平,复制数据的操作并不会很繁琐。再加上 schema 这样的数据格式约定,完全可以自动完成这项操作,比如在更新数据的方法
Store.prototype.upsert()中处理。 -
对提供给 React 订阅的数据流进行拆分。数据流中流动的数据,如果存储的是多层嵌套的数据,可以将被嵌套的数据也以数据流的形式提供给视图。例如,对于歌单,嵌套了歌曲列表的数据。视图
<Playlist />订阅了数据流playlist$,playlist$中流动是歌单数据,其中以有序列表的形式嵌套了流动着歌曲类型的数据流track1$-trackN$。由视图中的子组件<TrackItem />负责对其进行订阅。const Playlist = () => {
const { payload = {} } = useObservable(() => playlist$);
const { views } = payload;
return (
<Name>{ payload.name }</Name>
<TrackList>
{
views.tracks.map(track => <TrackItem track$={track.$} key={track.id} />)
}
</TrackList>
);
};
const TrackItem = ({ track$ }) => {
const data = useObservable(() => track$);
return (
<Name>{ data.name }</Name>
);
};这样可以一直分形下去,让每一级组件负责订阅自己所需的数据流。这样,
<Playlist />不再订阅歌曲项的数据流动,歌曲项的变化不会引起歌单自身区域的重新计算。但带来的问题是,每一级组件上都被数据流侵入,都出现了数据处理的逻辑,组件的props基本上仅剩下了一个数据流。视图层将不再轻量,所有组件需要基于数据流的思想进行改造,无法与其他基于 Redux 等框架的数据方案共用相同的组件。
可以根据实际情况选择合适的方式,或者选择结合两种方式。
总结
- 万物皆可数据流
- 多种方法组合数据流,直观描述数据计算、组合的逻辑
- 订阅触发数据流动
- 取消订阅考虑回收